DEMOINTVAL Interval computations in INTLAB
In this demo details are explained how to obtain verified inclusions of results in floating-point arithmetic. Results are true with mathematical rigor.
Contents
- Changing the rounding mode
- How to define an interval I
- How to define an interval II
- How to define an interval III
- How to define an interval IV
- How to define an interval V
- Output formats of intervals I
- Output formats of intervals II
- Rigorous output
- What you see is correct
- Output formats of intervals III
- Changing interval output permanently
- Display with uncertainty
- Newton iteration
- Bit representation
- Invoking interval operations
- Interval matrix operations
- Sharp interval multiplication
- Fast interval multiplication
- Acceleration by vector/matrix notation
- Overestimation of interval operations
- Interval standard functions
- Complex interval standard functions
- Standard functions with argument out of range
- A common misuse of interval arithmetic
- Rigorous solution of linear systems
- Accuracy of rigorous linear system solving: Hilbert matrices
- Extremely ill-conditioned linear systems
- Verification of regularity of extremely ill-conditioned matrices
- Structured linear systems
- Sparse linear systems
- Inclusion of eigenvalues and eigenvectors
- Eigenvalue pairs and invariant subspaces
- All eigenpairs of a matrix
- Eigenvalues of structured matrices
- Nonlinear systems of equations, polynomials, etc.
- Enjoy INTLAB
Changing the rounding mode
A key to interval operations in INTLAB is changing the rounding mode. There are four roundings modes switched by the command
setround(rnd)
Here rnd = 0 corresponds to "rounding to nearest", rnd = -1 to "rounding downwards (towards -inf)", rnd = 1 to "rounding upwards (towards +inf)" and rnd = 2 to "chop rounding (towards zero)". Once the rounding mode is changed, all subsequent operations are executed in that rounding mode until the next change.
Following we ensure "rounding to nearest".
setround(0) % rounding to nearest
How to define an interval I
There are four possibilities to generate an interval, the first is a simple typecast of a real or complex quantity, for example a matrix. It uses Matlab conversion, i.e. after the following statement the first component of u does not contain "2.3". This is because Matlab first converts "2.3" into binary format, and then the type cast is called.
format compact long infsup u = intval( [ 2.3 -4e1 ; 3 0 ] )
intval u = [ 2.29999999999999, 2.30000000000000] [ -40.00000000000000, -40.00000000000000] [ 3.00000000000000, 3.00000000000000] [ 0.00000000000000, 0.00000000000000]
INTLAB's output is correct, i.e., the displayed digits are true bounds for the result. The right bound of u(1) is 2.3. Since 2.3 is not a floating-point number, the real number 2.3 cannot be in the interval entry u(1). This is verified by inspecting the bit pattern of u(1):
getbits(u(1))
ans =
4×62 char array
'infimum '
' +1.0010011001100110011001100110011001100110011001100110 * 2^1'
'supremum '
' +1.0010011001100110011001100110011001100110011001100110 * 2^1'
As can be seen, u(1) is a point interval, i.e., the left and right bound coincide, and that number cannot be equal to the real number 2.3.
How to define an interval II
The second possibility is to use INTLAB conversion of constants. In this case the argument is a string and INTLAB's verified conversion to binary is called rather than Matlab conversion.
u = intval( '0.1 -3.1 5e2 .3e1' )
intval u = 1.0e+002 * [ 0.00099999999998, 0.00100000000001] [ -0.03100000000001, -0.03099999999998] [ 5.00000000000000, 5.00000000000000] [ 0.03000000000000, 0.03000000000000]
The first component, for example, definitely contains "0.1". Since 0.1 is not finitely representable in binary format, the radius of the first component must be nonzero.
u.rad
ans =
1.0e-15 *
0.013877787807814
0.444089209850063
0
0
Generating an interval by an input string always produces a column vector. To change "u" into a 2 x 2 matrix, use
reshape(u,2,2)
intval ans = 1.0e+002 * [ 0.00099999999998, 0.00100000000001] [ 5.00000000000000, 5.00000000000000] [ -0.03100000000001, -0.03099999999998] [ 0.03000000000000, 0.03000000000000]
Note that, although programmed in C, arrays are stored columnwise in Matlab.
How to define an interval III
The third possibility is by specification of midpoint and radius.
u = midrad( [ -3e1+2i ; .4711 ; 3 ] , 1e-4 )
intval u = [ -30.00010000000001 + 1.99989999999999i, -29.99989999999999 + 2.00010000000001i] [ 0.47099999999998 - 0.00010000000001i, 0.47120000000001 + 0.00010000000001i] [ 2.99989999999999 - 0.00010000000001i, 3.00010000000001 + 0.00010000000001i]
How to define an interval IV
The fourth possibility is by specification of infimum and supremum
u = infsup( [ 1 2 ] , [ 4 7 ] )
intval u = [ 1.00000000000000, 4.00000000000000] [ 2.00000000000000, 7.00000000000000]
How to define an interval V
Yet another possibility is to use [infimum,supremum] or midpoint,radius or giving significant digits in a string:
u = intval('[3,4] <5,.1> 1.23_')
intval u = [ 3.00000000000000, 4.00000000000000] [ 4.89999999999999, 5.10000000000001] [ 1.21999999999999, 1.24000000000001]
Output formats of intervals I
The output format can be changed using the different Matlab formats, for example
format midrad long e X = midrad( [ -3e1+2i ; .4711 ; 3 ] , 1e-4 )
intval X = < -3.000000000000000e+01 + 2.000000000000000e+00i, 1.000000000000001e-004> < 4.711000000000000e-01 + 0.000000000000000e+00i, 1.000000000001111e-004> < 3.000000000000000e+00 + 0.000000000000000e+00i, 1.000000000000001e-004>
or
format infsup long X
intval X = [ -30.00010000000001 + 1.99989999999999i, -29.99989999999999 + 2.00010000000001i] [ 0.47099999999998 - 0.00010000000001i, 0.47120000000001 + 0.00010000000001i] [ 2.99989999999999 - 0.00010000000001i, 3.00010000000001 + 0.00010000000001i]
or with a common exponent
1e4*X
intval ans = 1.0e+005 * [ -3.00001000000001 + 0.19998999999999i, -2.99998999999999 + 0.20001000000001i] [ 0.04709999999999 - 0.00001000000001i, 0.04712000000001 + 0.00001000000001i] [ 0.29998999999999 - 0.00001000000001i, 0.30001000000001 + 0.00001000000001i]
Output formats of intervals II
With two arguments the functions infsup and midrad define an interval, with one argument they control the output of an interval:
format short
u = infsup( [ 1 2 ] , [ 4 7 ] );
infsup(u), midrad(u)
intval u = [ 1.0000, 4.0000] [ 2.0000, 7.0000] intval u = < 2.5000, 1.5000> < 4.5000, 2.5000>
Rigorous output
Note that output in INTLAB is rigorous. That means,
left <= ans <= right for inf/sup notation ans in mid+/-rad for mid/rad notation
where ans is the true (real or complex) answer, and left,right, mid,rad are the numbers corresponding to the displayed decimal figures.
What you see is correct
Consider
format short midrad x = midrad(-5,1e-20)
intval x = < -5.0000, 0.0001>
One might get the impression that this is a very crude inclusion and display. However, the radius of the interval is nonzero. Hence, in four decimal places, the displayed radius 0.0001 is the best possible. Changing the display format gives more information:
format long
x
intval x = < -5.00000000000000, 0.00000000000001>
or even
format longe
x
intval x = < -5.000000000000000e+00, 8.881784197001254e-016>
Output formats of intervals III
A convenient way to display narrow intervals is the following:
x = midrad(pi,1e-8); format short, infsup(x), midrad(x), disp_(x) format long, infsup(x), midrad(x), disp_(x) format short
intval x =
[ 3.1415, 3.1416]
intval x =
< 3.1416, 0.0001>
intval x =
3.1415
intval x =
[ 3.14159264358979, 3.14159266358980]
intval x =
< 3.14159265358979, 0.00000001000001>
intval x =
3.1415927_______
Mathematically the following is true: Form an interval of the displayed midpoint and a radius of 1 unit of the last displayed decimal figure, then this is a correct inclusion of the stored interval. Hence the last display of x means that x is contained in [3.1415926,3.1415928]. The display by "format _" if particualarly useful for very narrow intervals:
format _ x = midrad(pi,1e-16) format infsup x
intval x =
3.1415
intval x =
[ 3.1415, 3.1416]
In the second display we have to compare all digits of the left and right bound to find out that the interval is indeed very narrow.
Changing interval output permanently
The interval output format can be changed permanently, for example, to infimum/supremum notation:
u = midrad( [ -3e1+2i ; .4711 ; 3 ] , 1e-4 );
format infsup
u
intval u = [ -30.0002 + 1.9998i, -29.9998 + 2.0002i] [ 0.4709 - 0.0002i, 0.4713 + 0.0002i] [ 2.9998 - 0.0002i, 3.0002 + 0.0002i]
or to midpoint/radius notation:
format midrad
u
intval u = < -30.0000 + 2.0000i, 0.0002> < 0.4711 + 0.0000i, 0.0002> < 3.0000 + 0.0000i, 0.0002>
or to display with uncertainties depicted by "_":
format _
u
intval u = -30.0000 + 2.0000i 0.4711 + 0.000_i 3.0000 + 0.000_i
Display with uncertainty
Display with uncertainty makes only sense for sufficiently narrow intervals. If the accuracy becomes too poor, INTLAB changes automatically to inf-sup or mid-rad display for real or complex intervals, respectively:
for k=-5:-1 disp_(midrad(pi,10^k)) end
intval =
3.1416
intval =
3.142_
intval =
3.14__
intval =
3.1___
[ 3.0415, 3.2416]
Newton iteration
The following code is an interval Newton iteration to compute an inclusion of sqrt(2).
format long _ f = @(x)(x^2-2); % Function f(x) = x^2-2 X = infsup(1.4,1.7); % Starting interval for i=1:4 xs = X.mid; % Midpoint of current interval Y = f(gradientinit(X)); % Gradient evaluation of f(X) X = intersect( X , xs-f(intval(xs))/Y.dx ) % Interval Newton step with intersection end
intval X = 1.4_____________ intval X = 1.4142__________ intval X = 1.414213562_____ intval X = 1.41421356237309
The "format _" output format shows nicely the quadratic convergence.
The last displayed result (which is in fact an interval) proves that the true value of sqrt(2) is between 1.41421356237308 and 1.41421356237310. Indeed, sqrt(2)=1.41421356237309504...
The format "long e" in Matlab displays the most figures. With this we see that the internal accuracy of the final X is in fact even better, the width is only 2 units in the last place.
format long e X format short
intval X = 1.414213562373095e+000
Bit representation
The bit pattern of floating-point numbers and of intervals as well is displayed as follows.
getbits(X)
ans =
4×62 char array
'infimum '
' +1.0110101000001001111001100110011111110011101111001011 * 2^0'
'supremum '
' +1.0110101000001001111001100110011111110011101111001101 * 2^0'
That shows that indeed the left and right bounds of X coincide up to 2 bits.
Invoking interval operations
An operation is executed as an interval operation if at least one of the operands is of type intval. For example, in
u = intval(5); y = 3*u-exp(u)
intval y = -133.4131
the result y is an inclusion of 15-exp(5). However, in
u = intval(5); z = 3*pi*u-exp(u)
intval z = -101.2892
the first multiplication "3*pi" is a floating point multiplication. Thus it is not guaranteed that the result z is an inclusion of 15pi-exp(5).
The following ensures a correct inclusion of the mathematical 3 \pi u - exp(u):
Z = 3*intval('pi')*u - exp(u) format long infsup(Z) format short
intval Z = -101.2892 intval Z = 1.0e+002 * [ -1.01289269298730, -1.01289269298729]
Interval matrix operations
INTLAB is designed to be fast. Case distinctions in interval multiplication can slow down computations significantly due to interpretation overhead. Therefore, there is a choice between 'fast' and 'sharp' evaluation of interval matrix products. This applies only to 'thick' intervals, i.e. intervals with nonzero diameter. In fact, there is only a significant difference of the results for very wide intervals.
Sharp interval multiplication
In the following example, c is a real random matrix, C is an interval matrix with diameter zero (a thin interval matrix), and CC is an interval matrix with nonzero diameter (a thick interval matrix), all of dimension nxn for n=1000. First we measure the computing time with option 'SharpIVmult'.
n = 1000; c = randn(n); C = intval(c); C_ = midrad(c,.1); intvalinit('SharpIVmult') tic, scc = c*c; fprintf('thin point * thin point %7.2f\n',toc) tic, sCC = C*C; fprintf('thin interval * thin interval %7.2f\n',toc) tic, sCC = C*C_; fprintf('thin interval * thick interval %7.2f\n',toc) tic, sCC__ = C_*C_; fprintf('thick interval * thick interval %7.2f\n',toc)
===> Slow but sharp interval matrix multiplication in use thin point * thin point 0.01 thin interval * thin interval 0.04 thin interval * thick interval 0.07 thick interval * thick interval 10.02
As can be seen, there is not much penalty if not both matrices are thick interval matrices; for both thick intervals, however, computation is slowed down significantly.
Fast interval multiplication
intvalinit('FastIVmult') tic, fcc = c*c; fprintf('thin point * thin point %7.2f\n',toc) tic, fCC = C*C; fprintf('thin interval * thin interval %7.2f\n',toc) tic, fCC = C*C_; fprintf('thin interval * thick interval %7.2f\n',toc) tic, fCC__ = C_*C_; fprintf('thick interval * thick interval %7.2f\n',toc) ratioDiameter = max(max(diam(fCC__)./diam(sCC__)))
===> Fast interval matrix multiplication in use (maximum overestimation
factor 1.5 in radius, see FAQ)
thin point * thin point 0.02
thin interval * thin interval 0.04
thin interval * thick interval 0.05
thick interval * thick interval 0.09
ratioDiameter =
1.0623
As can be seen there is again not much penalty if not both matrices are thick. However, the 'fast' implementation is much faster than the 'sharp' at the cost of a little wider output, some 6 percent wider. If intervals are very wide and any overestimation cannot be afforded (as in global optimization), the option 'SharpIVmult' may be used. It is shown in
S.M. Rump: Fast and parallel interval arithmetic. BIT Numerical Mathematics, 39(3):539-560, 1999
that the maximum (componentwise) overestimation by the option 'FastIVmult' compared to 'SharpIVmult' is a factor 1.5, for real and complex intervals. This factor is only achievable for extremely wide intervals. For not too thick intervals, however, it is shown that the overestimation is negligible.
Acceleration by vector/matrix notation
It is advisable to use vector/matrix notation when using interval operations. Consider
n = 10000; x = 1:n; y = intval(x); tic for i=1:n y(i) = y(i)^2 - y(i); end t1 = toc
t1 =
4.2494
This simple initialization takes considerable computing time. Compare to
tic y = intval(x); y = y.^2 - y; t2 = toc ratio = t1/t2
t2 =
0.0065
ratio =
649.3294
Sometimes code looks more complicated, a comment may help. It is worth it.
Overestimation of interval operations
Note that the main principle of interval arithmetic is that for given intervals A,B and an operation o, the result a o b is included in the interval result A o B for all a in A and all b in B. Since the result must be an interval, overestimations cannot be avoided in many situations. For example, in
close, kmax = 40; i = sqrt(-1); a=midrad(2,.7); b=midrad(1-i,1); plotintval(3*a-exp(b)); hold on phi = linspace(0,2*pi,kmax); [A,B] = meshgrid( mid(a)+rad(a)*exp(i*phi) , mid(b)+rad(b)*exp(i*phi) ); plot(3*A-exp(B)) hold off
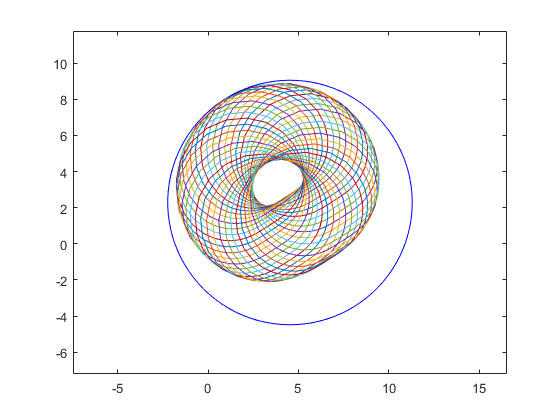
the blue circle is the result of INTLAB's interval operation, whereas the many circles approximate the power set operation (see also the DEMOINTLAB). Another reason for overestimation are dependencies, see below.
Interval standard functions
Interval standard functions in INTLAB are rigorous. For a given interval X and a function f let Y be the computed value of f(X). Then f(x) is in Y for all x in X. For example
x = intval(1e10); format long
sin(x)
intval ans = -0.48750602508751
Note that the result is rigorous (try sin(2^1000) or similar) because of the very accurate and rigorous range reduction in INTLAB. For timing comparison consider
format short
n = 10000; x = random(n,1); X = intval(x);
tic, exp(x); tapprox = toc
tic, exp(X); trigorous = toc
ratio = trigorous/tapprox
tapprox =
4.4070e-04
trigorous =
0.0078
ratio =
17.5911
Complex interval standard functions
Complex interval standard functions are rigorous as well, for example
format long
Z = midrad(3+4i,1e-7);
res = sin(Z)
intval res = 3.85374_________ - 27.01681_________i
It is mathematically correct, that sin(z) is an element of res for every complex z with Euclidian distance less than or equal to 1e-7 from 3+4i.
Standard functions with argument out of range
When entering a real argument leading to a complex value of a standard function, there are three possibilities to be specified by intvalinit:
intvalinit('RealStdFctsExcptnNan'); sqrt(intval(-2)) intvalinit('RealStdFctsExcptnWarn'); sqrt(intval(-2)) intvalinit('RealStdFctsExcptnAuto'); sqrt(intval(-2))
===> Result NaN for real interval input out of range
intval ans =
NaN
===> Complex interval stdfct used automatically for real interval input
out of range, but with warning
intval ans =
-0.00000000000000 + 1.41421356237309i
===> Complex interval stdfct used automatically for real interval input
out of range (without warning)
intval ans =
-0.00000000000000 + 1.41421356237309i
A common misuse of interval arithmetic
The dependency problem is the most serious problem of (naive) interval arithmetic. The following statement is mathematically correct:
" Take some numerical algorithm and replace every operation by its corresponding interval operation. Then, if the algorithm does not end prematurely, the computed interval result(s) contain the true result which would be obtained without the presence of rounding errors. "
However, that method will most certainly fail in practice. Although the statement is true, the computed result interval(s) will - even for toy problems - most certainly be of huge diameter and thus useless. For very modest problem size most certainly an exception like divide by a zero interval will occur.
Consider, for example, the triangular matrix T where all elements on and below the diagonal are equal to 1, and take a randomly generated right hand side. The following code does this for dimension n = 50:
n = 50; T = tril(ones(n)); b = randn(n,1);
Then perform a standard forward substitution to compute an inclusion T\b. Note that X is defined to be an interval vector, so all operations are indeed interval operations (see above section "Invoking interval operations").
X = intval(zeros(n,1)); for i=1:n X(i) = b(i) - T(i,1:i-1)*X(1:i-1); end X
intval X = 0.38103700906351 -1.56573815891574 1.06018189486388 0.16709089528503 1.53981492594006 -3.06410737335499 1.12604630669418 0.9402562605143_ 0.1480566593502_ -2.320201480767__ -0.363452948259__ 3.633211388728__ -2.113347927985__ 0.89229786087___ -1.61785152877___ 1.60332850088___ 0.08452757497___ -1.1843775937____ 0.7940128822____ 0.5423268157____ -1.414955646_____ 1.882897939_____ 0.088421822_____ 0.50790459______ -1.49714119______ -0.11275684______ -0.4037820_______ 0.1748937_______ -0.9226383_______ 1.3435029_______ -2.031445________ 2.980005________ -1.381092________ -1.14295_________ 1.45136_________ 0.08084_________ -0.43890_________ -0.2705__________ -0.2612__________ -0.7708__________ -0.893___________ 1.644___________ 2.057___________ -2.50____________ -0.49____________ 1.32____________ -0.2_____________ 1.1_____________ -0.4_____________ 0.6_____________
The result is displayed with uncertainty, making perfectly visible the exponential loss of accuracy. This is due to one of the most common misuses of interval arithmetic called "naive interval arithmetic". For more details and examples cf.
S.M. Rump: Verification methods: Rigorous results using floating-point arithmetic. Acta Numerica, 19:287-449, 2010.
to be downloaded from "www.ti3.tuhh.de/rump". See, in particular,
Chapter 10.1: The failure of the naive approach: Interval Gaussian elimination (IGA)
where I proved that Interval Gaussian elimination (IGA) must fail unless the matrix has very special properties. The failure is independent of the condition number, for example, for orthogonal matrices the method fails for toy dimensions.
Note that the linear system above is very well-conditioned:
cond(T)
ans = 64.270085531579468
By the well-known rule of thumb of numerical analysis we expect at least 14 correct digits in a floating-point approximation T\b. Using a proper (non-naive) method, an inclusion of this quality is indeed achieved:
Xverify = verifylss(T,b)
intval Xverify = 0.38103700906351 -1.56573815891574 1.06018189486388 0.16709089528503 1.53981492594005 -3.06410737335499 1.12604630669417 0.94025626051430 0.14805665935021 -2.32020148076715 -0.36345294825918 3.63321138872799 -2.11334792798499 0.89229786086866 -1.61785152877099 1.60332850088165 0.08452757497098 -1.18437759370235 0.79401288215436 0.54232681570451 -1.41495564641732 1.88289793931729 0.08842182173849 0.50790459039567 -1.49714119499960 -0.11275683800331 -0.40378203738056 0.17489370851248 -0.92263828603709 1.34350290990128 -2.03144511580698 2.98000476903683 -1.38109214976310 -1.14294866019694 1.45136339740994 0.08083518908047 -0.43889946081862 -0.27049393626730 -0.26115780076378 -0.77076259212050 -0.89348829111919 1.64395144966166 2.05734502342590 -2.49995673800958 -0.49003553108938 1.31527164993313 -0.24404089658298 1.06159055194396 -0.44656624918969 0.57097487326767
As can be seen, there is no "_", all digits of all entries are displayed. That means, the inclusion is maximally accurate:
max(relerr(Xverify))
ans =
2.186075352932433e-16
Such methods are called "self-validating methods" or "verification methods". For some details see the reference above or
S.M. Rump: Self-validating methods. Linear Algebra and its Applications (LAA), 324:3-13, 2001.
Due to accurate evaluation of the residual 15 correct decimal digits of the result are computed.
Rigorous solution of linear systems
The INTLAB linear system solver can be called with "\" or "verifylss".' For example,
n = 100; A = randn(n); b = A*ones(n,1); X = verifylss(A,b);
generates and solves a randomly generated 100x100 linear system. The inclusion and its quality is checked by
X([1:3 98:100]) max( X.rad ./ abs(X.mid) )
intval ans =
1.00000000000000
0.99999999999999
0.99999999999998
1.00000000000000
0.99999999999999
1.00000000000000
ans =
2.220446049250313e-16
which calculates the maximum relative error of the inclusion radius with respect to the midpoint. The same is done by
max(relerr(X))
ans =
2.220446049250313e-16
Accuracy of rigorous linear system solving: Hilbert matrices
For estimating accuracy, try
format long e _ n = 10; H = hilb(n); b = ones(n,1); X = H\intval(b)
intval X = -9.99830187738504_e+000 9.89853315105809_e+002 -2.375687668243377e+004 2.402116154434528e+005 -1.261124656403665e+006 3.783408062580753e+006 -6.726109956010935e+006 7.000690639898561e+006 -3.937910678885931e+006 9.23711993869239_e+005
Here we use Matlab's backslash operator but make sure that at least on argument (the matrix or the right hand side) is of type intval. That ensures that a verified inclusion is computed.
The notoriously ill-conditioned Hilbert matrix is given by H_ij := 1/(i+j-1). To estimate the accuracy, we use the symbolic toolbox to compute the perturbation of the solution when perturbing only the (7,7)-element of the input matrix by 2^(-52):
Hs = sym(H,'f');
Hs(7,7) = Hs(7,7)*(1+sym(2^(-52)));
double( Hs \ b )
ans =
-9.997198050336207e+00
9.897576960772726e+02
-2.375483680969619e+04
2.401930526008937e+05
-1.261036061017173e+06
3.783164425266260e+06
-6.725710140930751e+06
7.000304229698808e+06
-3.937707813532462e+06
9.236673822756851e+05
The statement "sym(H,'f')" makes sure that no conversion error occurs when changing H into symbolic format.
Extremely ill-conditioned linear systems
By default, all computations in INTLAB are, like in Matlab, performed in double precision. This restricts treatable linear systems to a maximum condition number of roughly below 10^16.
Starting with INTLAB Version 7, I rewrote my linear system solver completely. Now, although only double precision is used, linear systems with larger condition numbers are solvable. Consider
format long _ n = 20; A = invhilb(n); condA = norm(double(inv(sym(A))))*norm(A)
condA =
5.478702657981727e+27
The common rule of thumb tells that for a condition number 10^k, an algorithm in double precision should produce 16-k correct digits. In our case this means roughly 16-27=-11 "correct" digits, namely none. For a random right hand side Matlab computes
b = A*randn(n,1); x = A\b
x = 1.0e+03 * -6.658294004044903 -0.255758659289816 0.336006616943621 0.090129248181610 -0.081439573657559 -0.120644009456883 -0.095418195159896 -0.056257261583536 -0.028053654733106 -0.009187180837811 -0.000701111020640 0.001351151888638 -0.000244872607491 -0.001967095244288 -0.001099272757779 0.000400533283715 0.000066641071115 0.003902392190012 0.003577571416473 -0.000631628569556
A corresponding warning indicates the difficulty of the problem. Note that in this case the Matlab guess of the condition number is pretty good.
A verified inclusion of the solution is computed by
X = verifylss(A,b,'illco')
intval X = 1.0e+004 * 2.229___________ 0.55793_________ 0.0691269_______ -0.0445287274____ -0.05038826892___ -0.033401026663__ -0.0176316192499_ -0.0076403191785_ -0.00279867273996 -0.00061695285538 0.00004351671595 0.00008303183618 -0.00010732897367 -0.00023091845390 -0.00011711298106 -0.00005126597527 -0.00033785756670 -0.00040086733705 -0.00106976273533 -0.00229344391511
As expected the Matlab approximation differs significantly from the true values, for some components the sign is incorrect. The maximum relative error of the components of the computed inclusion is
max(relerr(X))
ans =
7.006628162934414e-05
so that each component is accurately included with at least 7 correct figures.
Verification of regularity of extremely ill-conditioned matrices
Previously I used for accurate dot product computations some reference implementations. They suffer from interpretation overhead. and made it time consuming to solve linear systems with extremely ill-conditioned matrix.
From Version 14 there are the very fast and versatile routines prodK and spProdK included in INTLAB. They are often faster than the highly optimized Advanpix Multiple precision package by Pavel Holoborodko:
P. Holoborodko: Multiprecision Computing Toolbox for MATLAB, Advanpix LLC., Yokohama, Japan, 2019.
For details of performance and how to use prodK and spProdk cf. the demos daccmatprod and dprodK.
Checking regularity of very extremely ill-conditioned matrices can be done very fast using mod-p arithmetic. Consider
n = 50;
cnd = 1e200;
digits(400)
A = randmat(n,cnd);
tic, Cnd = norm(A,inf)*norm(double(inv(sym(A,'f'))),inf), toc
Cnd =
4.345046218778444e+226
Elapsed time is 3.528243 seconds.
As can be seen the matrix A is indeed extremely ill-conditioned. However, checking regularity in mod-p arithmetic is rigorous and very fast:
tic, isregular(A), toc
ans =
1
Elapsed time is 0.013098 seconds.
With a chance of about 1/p regularity cannot be checked. Since p is of the order 1e8, this chance is slim. It can be further diminished by using several primes, see "help isregular".
Note that verification of regularity, i.e. a sufficient criterion, is simple, whereas a necessary and sufficient check of singularity is an NP-hard problem.
Structured linear systems
In general, intervals are treated as independent quantities. If, however, there are dependencies, then taking them into account may shrink the solution set significantly. An example is
format short n = 4; e = 1e-3; intvalinit('displayinfsup'); A = midrad( toeplitz([0 1+e e 1+e]),1e-4); b = A.mid*ones(n,1); Amid = A.mid X1 = verifylss(A,b)
===> Default display of intervals by infimum/supremum (e.g. [ 3.14 , 3.15 ])
Amid =
0 1.0010 0.0010 1.0010
1.0010 0 1.0010 0.0010
0.0010 1.0010 0 1.0010
1.0010 0.0010 1.0010 0
intval X1 =
[ 0.3327, 1.6673]
[ 0.3327, 1.6673]
[ 0.3327, 1.6673]
[ 0.3327, 1.6673]
First the matrix has been treated as a general interval matrix without dependencies. Recall that only the midpoint is displayed above; all entries of the interval matrix have a uniform tolerance of 1e-4.
Several structural information may be applied to the input matrix, for example,
X2 = verifystructlss(structure(A,'symmetric'),b); X3 = verifystructlss(structure(A,'symmetricToeplitz'),b); X4 = verifystructlss(structure(A,'generalToeplitz'),b); X5 = verifystructlss(structure(A,'persymmetric'),b); X6 = verifystructlss(structure(A,'circulant'),b); res = [ X1 X2 X3 X4 X5 X6 ]; rad(res)
ans =
0.6672 0.5062 0.1689 0.3376 0.5062 0.0003
0.6672 0.5062 0.1688 0.3375 0.5062 0.0003
0.6672 0.5062 0.1688 0.3375 0.5062 0.0003
0.6672 0.5062 0.1689 0.3376 0.5062 0.0003
The columns are the radii of the inclusions X1 ... X6. Note that the inclusion may become much narrower, in particular treating the input data as a circulant matrix.
Sparse linear systems
The following generates a random sparse system with about 9 nonzero elements per row.
format short
n = 10000; A = sprand(n,n,2/n)+speye(n); A = A*A'; b = ones(n,1);
The linear system is generated to be symmetric positive definite. Before calling the verified linear system solver, the fill-in should reduced. The original matrix looks like
spy(A)
title('sparsity pattern of A')
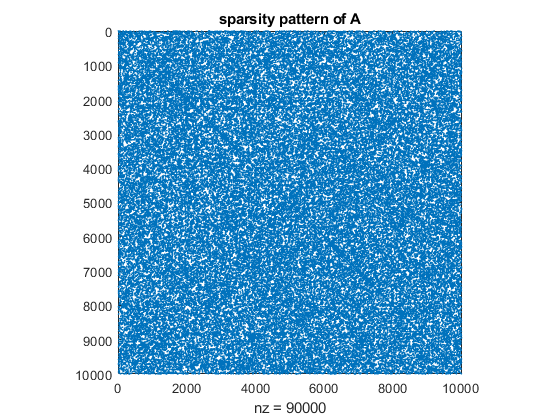
whereas after minimum degree reordering the matrix looks like
p = symamd(A);
spy(A(p,p))
title('sparsity pattern of renumbered A')
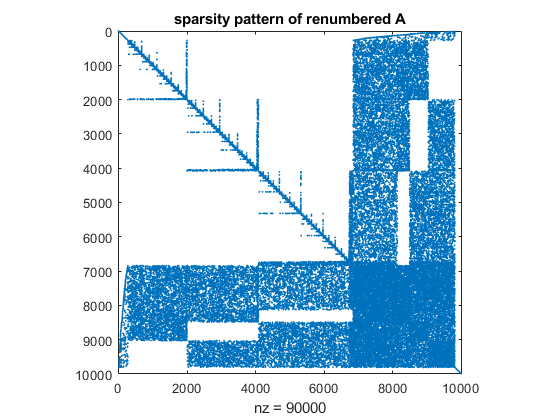
The timing for the built-in (floating point) solver compared to the verified solver is as follows:
tic, x = A(p,p)\b(p); toc
Elapsed time is 0.175343 seconds.
tic, X = verifylss(A(p,p),b(p)); toc
Elapsed time is 1.060415 seconds.
From Version 14 of INTLAB there are sparse solvers for systems linear and nonlinear equations as well as underdetermined systems and least squares problems. For details see the demo dsparse.
Inclusion of eigenvalues and eigenvectors
To compute verified inclusions of eigenvalue/eigenvector pairs of simple or multiple eigenvalues, consider, for example, the famous Wilkinson(21) matrix. Following inclusions of the last four eigenvalue/eigenvector pairs are displayed. Those are the most ill-conditioned.
format long _ W = wilkinson(21); % generation of the matrix [V,D] = eig(W); % eigenvalue/eigenvector approximations for k=18:21 [L,X] = verifyeig(W,D(k,k),V(:,k)) % inclusions for the small eigenvalues end
intval L = 9.21067864730491 intval X = -0.38247_________ 0.301890________ 0.44607_________ 0.238157________ 0.080419________ 0.0200421_______ 0.00397193______ 0.00065440______ 0.000092313_____ 0.0000112430____ -0.00000000000___ -0.000011243042__ -0.0000923130036_ -0.00065439636234 -0.00397193251082 -0.02004206756034 -0.08041877341334 -0.23815677108033 -0.44606931512504 -0.30188982395948 0.38246757537813 intval L = 9.21067864736133 intval X = 0.38246757533800 -0.30188982390622 -0.44606931509072 -0.23815677111720 -0.08041877354260 -0.02004206794300 -0.00397193399399 -0.00065440370822 -0.0000923571434_ -0.000011553974__ -0.00000250882___ -0.0000115540____ -0.000092357_____ -0.00065440______ -0.0039719_______ -0.0200421_______ -0.080419________ -0.238157________ -0.44607_________ -0.301890________ 0.38247_________ intval L = 10.74619418290332 intval X = 0.55939864230126 0.41742001280922 0.16949775589362 0.04805373844102 0.01052087952088 0.00188039874002 0.0002842567806_ 0.0000372526996_ 0.00000430986___ 0.00000044221___ 0.0000000000____ -0.000000442_____ -0.00000431______ -0.0000372_______ -0.000284________ -0.00188_________ -0.0105__________ -0.048___________ -0.169___________ -0.417___________ -0.56____________ intval L = 10.74619418290339 intval X = 0.56____________ 0.42____________ 0.169___________ 0.048___________ 0.0105__________ 0.00188_________ 0.000284________ 0.000037________ 0.00000431______ 0.000000451_____ 0.0000000839____ 0.0000004509____ 0.000004310876__ 0.0000372528328_ 0.0002842568009_ 0.00188039874370 0.01052087952170 0.04805373844125 0.16949775589369 0.41742001280919 0.55939864230118
Eigenvalue pairs and invariant subspaces
The largest eigenvalues are 10.74619418290332 and 10.74619418290339, where all displayed digits are verified to be correct. Invariant subspaces of nearby eigenvalues are in general ill-conditioned. Nearby eigenvalues can also be regarded as clusters. From the inclusions above we can judge how narrow the eigenvalues are. So one of the approximations can be used as an approximation of the pair.
[L,X] = verifyeig(W,D(18,18),V(:,18:19)) % inclusion of the 18/19 eigenvalue pair [L,X] = verifyeig(W,D(20,20),V(:,20:21)) % inclusion of the 20/21 eigenvalue pair
intval L = 9.2106786473____ + 0.0000000000____i intval X = -0.38246721566493 0.38246757533800 0.30188954003016 -0.30188982390622 0.44606889559399 -0.44606931509072 0.23815654709237 -0.23815677111720 0.08041869777897 -0.08041877354260 0.02004204871064 -0.02004206794300 0.00397192877519 -0.00397193399399 0.00065439574687 -0.00065440370821 0.00009231291679 -0.00009235714338 0.00001124303112 -0.00001155397350 -0.00000000000118 -0.00000250882017 -0.00001124304199 -0.00001155396293 -0.00009231300365 -0.00009235705656 -0.00065439636234 -0.00065440309275 -0.00397193251082 -0.00397193025836 -0.02004206756034 -0.02004204909331 -0.08041877341334 -0.08041869790822 -0.23815677108033 -0.23815654712923 -0.44606931512504 -0.44606889555967 -0.30188982395948 -0.30188953997691 0.38246757537813 0.38246721562480 intval L = 10.7461941829034_ + 0.0000000000000_i intval X = 0.55939864230126 0.53926516857120 0.41742001280922 0.40239653183024 0.16949775589362 0.16339731453128 0.04805373844102 0.04632422283758 0.01052087952089 0.01014221959041 0.00188039874009 0.00181272078417 0.00028425678094 0.00027402603484 0.00003725270198 0.00003591205802 0.00000430988244 0.00000415574012 0.00000044236679 0.00000043485205 0.00000000151024 0.00000008241241 -0.00000042613744 0.00000045076775 -0.00000415472850 0.00000431085765 -0.00003591192480 0.00003725283040 -0.00027402601454 0.00028425680050 -0.00181272078050 0.00188039874363 -0.01014221958959 0.01052087952169 -0.04632422283735 0.04805373844125 -0.16339731453120 0.16949775589369 -0.40239653183027 0.41742001280919 -0.53926516857129 0.55939864230118
Note that interval output with uncertainty ("_") is used, so all displayed decimal places of the bases of the invariant subspaces are verified to be correct. As explained in section "Output formats of intervals III", the inclusion 10.7461941829034_ of the two smallest eigenvalues reads [10.7461941829033,10.7461941829035], thus including the true eigenvalues as displayed above.
The mathematical statement is that the displayed intervals for the cluster contain (at least) two eigenvalues of the Wilkinson matrix W. The size of the cluster is determined by the number of columns of the invariant subspace approximation.
All eigenpairs of a matrix
From Version 14 of INTLAB there is a routine to compute inclusions of all eigenpairs of a matrix. Applied to Wilkinson's matrix the eigenvalues
L = eig(intval(W))
intval L = -1.12544152211998 0.25380581709667 0.94753436752929 1.78932135269508 2.13020921936251 2.96105888418573 3.04309929257883 3.99604820138362 4.00435402344086 4.99978247774290 5.00024442500191 6.00021752225710 6.00023403158417 7.00395179861637 7.00395220952868 8.03894111581427 8.03894112282902 9.21067864730492 9.21067864736133 10.74619418290332 10.74619418290339
are included with maximal accuracy, and the eigenvectors
[X,L] = verifyeigall(W); X
intval X = Columns 1 through 6 -0.00000002274322 -0.00000043432503 -0.0000018718132_ 0.0000112430366_ -0.0000200530968_ 0.0001165635515_ 0.00000025302835 0.0000042330161_ 0.0000169445247_ -0.0000923129602_ 0.0001578136761_ -0.0008204839754_ -0.00000253928055 -0.0000365884554_ -0.0001345733896_ 0.0006543960546_ -0.0010640938401_ 0.0048382908625_ 0.00002291902784 0.00027918826458 0.0009321296807_ -0.0039719306430_ 0.0060881945361_ -0.0235593787820_ -0.00018368793994 -0.0018468697910_ -0.0055071094677_ 0.0200420581355_ -0.0285841397828_ 0.0903166527631_ 0.00128593864653 0.01033328418502 0.02689235163930 -0.0804187355962_ 0.1045264460677_ -0.2509076107425_ -0.00769325404043 -0.0471969034982_ -0.10347322132685 0.2381566590864_ -0.2713848914750_ 0.4212691910505_ 0.03814538505249 0.16647548115111 0.28895610034195 -0.44606910535957 0.4029065220166_ -0.1867662726657_ -0.14967330133239 -0.40997709443497 -0.4895992439178_ 0.3018896819949_ -0.0790594868338_ -0.4139963039964_ 0.42964976568453 0.5494241362748_ 0.22633027756513 0.38246739552158 -0.4132007960804_ -0.2111085533101_ -0.76352215062263 0.00000000000000 0.47772468275803 0.0000000000000_ -0.3879438623443_ 0.0000000000000_ 0.42964976568453 -0.5494241362748_ 0.22633027756513 -0.3824673955216_ -0.4132007960804_ 0.2111085533101_ -0.14967330133239 0.40997709443497 -0.4895992439178_ -0.3018896819949_ -0.0790594868338_ 0.4139963039964_ 0.03814538505249 -0.16647548115111 0.28895610034195 0.4460691053596_ 0.4029065220166_ 0.1867662726657_ -0.00769325404043 0.04719690349823 -0.10347322132685 -0.2381566590864_ -0.2713848914750_ -0.4212691910505_ 0.00128593864653 -0.01033328418502 0.02689235163930 0.0804187355962_ 0.1045264460677_ 0.2509076107425_ -0.00018368793994 0.0018468697910_ -0.0055071094677_ -0.0200420581355_ -0.0285841397828_ -0.0903166527631_ 0.00002291902784 -0.00027918826458 0.0009321296807_ 0.0039719306430_ 0.0060881945361_ 0.0235593787820_ -0.00000253928055 0.0000365884554_ -0.0001345733896_ -0.0006543960546_ -0.0010640938401_ -0.0048382908625_ 0.00000025302835 -0.0000042330161_ 0.0000169445247_ 0.0000923129602_ 0.0001578136761_ 0.0008204839754_ -0.00000002274322 0.00000043432503 -0.0000018718132_ -0.0000112430366_ -0.0000200530968_ -0.0001165635515_ Columns 7 through 12 -0.0001269707692_ 0.000827063073__ -0.000830704619__ 0.0047977126____ -0.0047979301____ 0.022668235_____ 0.0008833230338_ -0.004965646827__ 0.004980610809__ -0.0239896065____ 0.0239884777____ -0.090668011_____ -0.0051348968355_ 0.024020794299__ -0.024050663728__ 0.0911659316____ -0.09115011747___ 0.249316074_____ 0.0245698507225_ -0.091212455712__ 0.091117326949__ -0.2495280190____ 0.2494395953____ -0.407909906_____ -0.0920855628698_ 0.249977026093__ -0.248904590141__ 0.4079443843____ -0.4076681039____ 0.158505102_____ 0.2477180152704_ -0.409729455341__ 0.405608116914__ -0.1585051023____ 0.1581288643____ 0.407944384_____ -0.3926739964539_ 0.161371597542__ -0.154937499524__ -0.4079099059____ 0.4077067545____ 0.249528019_____ 0.1280320097222_ 0.409091747285__ -0.406282718419__ -0.2493160742____ 0.2496775440____ 0.091165932_____ 0.3981920855003_ 0.246103501542__ -0.253114183375__ -0.0906680106____ 0.0917093608____ 0.023989606_____ 0.2873218729737_ 0.082142704322__ -0.101047713418__ -0.0226682354____ 0.0254729546____ 0.004797713_____ 0.1888350299147_ 0.000000000000__ -0.050468920993__ -0.00000000000___ 0.0101886838____ -0.000000000_____ 0.2873218729737_ -0.082142704322__ -0.101047713418__ 0.0226682354____ 0.0254729546____ -0.004797713_____ 0.3981920855003_ -0.246103501542__ -0.253114183375__ 0.0906680106____ 0.0917093608____ -0.023989606_____ 0.1280320097222_ -0.409091747285__ -0.406282718419__ 0.2493160742____ 0.2496775440____ -0.091165932_____ -0.3926739964539_ -0.161371597542__ -0.154937499524__ 0.4079099059____ 0.4077067545____ -0.249528019_____ 0.2477180152704_ 0.409729455341__ 0.405608116914__ 0.1585051023____ 0.1581288643____ -0.407944384_____ -0.0920855628698_ -0.249977026093__ -0.248904590141__ -0.40794438431___ -0.40766810387___ -0.158505102_____ 0.0245698507225_ 0.091212455712__ 0.091117326949__ 0.24952801902___ 0.2494395953____ 0.407909906_____ -0.0051348968355_ -0.024020794299__ -0.024050663728__ -0.0911659316____ -0.09115011747___ -0.249316074_____ 0.0008833230338_ 0.004965646827__ 0.004980610809__ 0.0239896065____ 0.0239884777____ 0.090668011_____ -0.0001269707692_ -0.000827063073__ -0.000830704619__ -0.0047977126____ -0.0047979301____ -0.022668235_____ Columns 13 through 18 -0.022668112_____ -0.0821427_______ -0.0821427_______ -0.21111_________ 0.21111_________ -0.3825__________ 0.090667145_____ 0.2461035_______ 0.2461034_______ 0.413996________ -0.41400_________ 0.3019__________ -0.249312103_____ -0.4090917_______ -0.4090914_______ -0.186766________ 0.186766________ 0.4461__________ 0.407898714_____ 0.1613716_______ 0.1613712_______ -0.421269________ 0.421269________ 0.2382__________ -0.158491150_____ 0.4097295_______ 0.4097292_______ -0.25091_________ 0.250908________ 0.0804__________ -0.407935806_____ 0.2499770_______ 0.24997731______ -0.090317________ 0.090317________ 0.0200__________ -0.249540126_____ 0.0912125_______ 0.0912134_______ -0.023559________ 0.02356_________ 0.0040__________ -0.091202846_____ 0.0240208_______ 0.0240233_______ -0.004838________ 0.00484_________ 0.0007__________ -0.024089756_____ 0.0049656_______ 0.0049747_______ -0.00082_________ 0.000821________ 0.0001__________ -0.005161817_____ 0.0008271_______ 0.0008699_______ -0.00012_________ 0.000121________ 0.0000__________ -0.001720539_____ 0.00000000______ 0.0002484_______ 0.000000________ 0.000030________ -0.0000__________ -0.005161817_____ -0.0008271_______ 0.0008699_______ 0.00012_________ 0.000121________ -0.0000__________ -0.024089756_____ -0.0049656_______ 0.0049747_______ 0.00082_________ 0.000821________ -0.0001__________ -0.091202846_____ -0.0240208_______ 0.0240233_______ 0.004838________ 0.00484_________ -0.0007__________ -0.249540126_____ -0.0912125_______ 0.0912134_______ 0.023559________ 0.02356_________ -0.0040__________ -0.407935806_____ -0.2499770_______ 0.24997731______ 0.090317________ 0.090317________ -0.0200__________ -0.158491150_____ -0.4097295_______ 0.4097292_______ 0.250908________ 0.25091_________ -0.0804__________ 0.407898714_____ -0.1613716_______ 0.1613712_______ 0.421269________ 0.421269________ -0.2382__________ -0.249312103_____ 0.4090917_______ -0.4090914_______ 0.186766________ 0.186766________ -0.4461__________ 0.090667145_____ -0.2461035_______ 0.2461034_______ -0.413996________ -0.413996________ -0.3019__________ -0.022668112_____ 0.0821427_______ -0.0821427_______ 0.211109________ 0.21111_________ 0.3825__________ Columns 19 through 21 0.3825__________ 0.6_____________ 0.5_____________ -0.3019__________ 0.4_____________ 0.4_____________ -0.4461__________ 0.2_____________ 0.2_____________ -0.238___________ 0.1_____________ 0.0_____________ -0.0804__________ 0.0_____________ 0.0_____________ -0.020___________ 0.0_____________ 0.0_____________ -0.0040__________ 0.0_____________ 0.0_____________ -0.001___________ 0.0_____________ 0.0_____________ -0.0001__________ 0.0_____________ 0.0_____________ -0.0000__________ 0.0_____________ 0.0_____________ -0.0000__________ 0.0_____________ 0.0_____________ -0.0000__________ -0.0_____________ 0.0_____________ -0.0001__________ -0.0_____________ 0.0_____________ -0.001___________ -0.0_____________ 0.0_____________ -0.0040__________ -0.0_____________ 0.0_____________ -0.020___________ -0.0_____________ 0.0_____________ -0.0804__________ -0.0_____________ 0.0_____________ -0.238___________ -0.1_____________ 0.1_____________ -0.4461__________ -0.2_____________ 0.2_____________ -0.3019__________ -0.4_____________ 0.4_____________ 0.3825__________ -0.5_____________ 0.6_____________
are included as well. However, due to the sensitivity of eigenvalue clusters the accuracy of the inclusions decreases.
Eigenvalues of structured matrices
As for linear systems, the interval input matrix may be structured. Taking into account such structure information may shrink the inclusion. As an example consider
format short e = 1e-3; A = midrad( toeplitz([0 1+e -e/2 1+e]),1e-4); [v,d] = eig(A.mid); xs = v(:,2:3); lambda = d(2,2); X1 = verifyeig(A,lambda,xs); X2 = verifystructeig(structure(A,'symmetric'),lambda,xs); X3 = verifystructeig(structure(A,'symmetricToeplitz'),lambda,xs); X4 = verifystructeig(structure(A,'generalToeplitz'),lambda,xs); X5 = verifystructeig(structure(A,'persymmetric'),lambda,xs); X6 = verifystructeig(structure(A,'circulant'),lambda,xs); res = [ X1 X2 X3 X4 X5 X6 ]; rad(res)
ans =
1.0e-03 *
0.7215 0.6405 0.3400 0.4804 0.5607 0.4000
As for linear systems, only the radii of the inclusions are displayed.
Nonlinear systems of equations, polynomials, etc.
For inclusions of systems of nonlinear equations, of roots of polynomials etc. see the corresponding demos.
Enjoy INTLAB
INTLAB was designed and written by S.M. Rump, head of the Institute for Reliable Computing, Hamburg University of Technology. Suggestions are always welcome to rump (at) tuhh.de